- PPT讲Single Host Queue是为了控制爬取同一个网站的频率,但是后面也提到需要通过crawl history table来看是否可以再crawl这个网站。所以这个Single Host Queue好像也没法自己实现这个功能?
- 另外如果这个Single Host Queue只是为了把相同domain的url group起来,那URL processor其实很大程度已经是这么做了:处理一个url时抓取的大部分都是同样domain的url。
- URL frontier的输入输出只有Url吗?或者说Queue里面存的data都只是url吗?没有涉及到例如分配哪个region的哪几个machine去crawl某个对应的url?
- 总之如果没有Single Host Queue, 是否一样可以根据priority crawl网页,而且可以通过crawl history知道现在这个url是不是该crawl了?
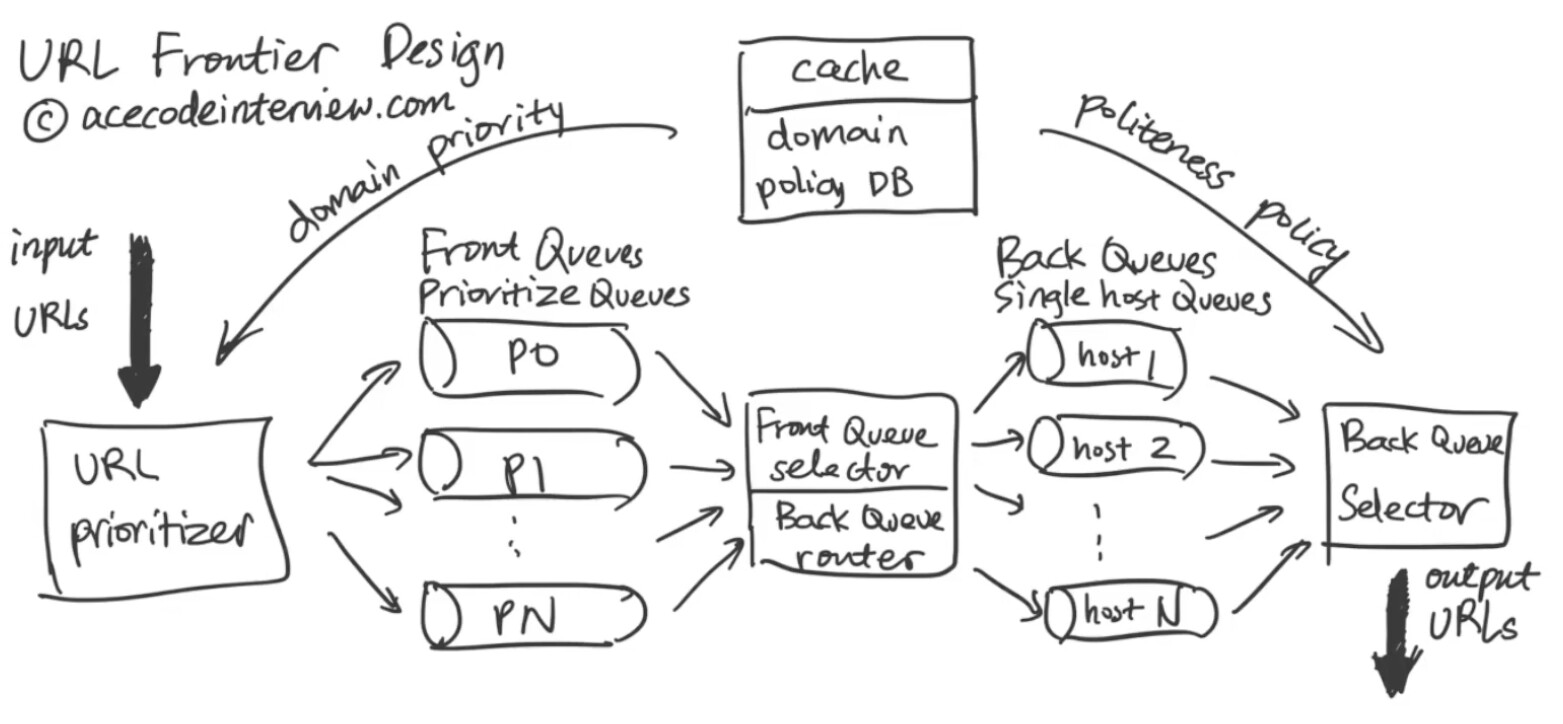
- Single Host Queue 控制的爬取频率指的是保证用户满足 Politeness 要求的频率。不是指一个网站每两周爬一次这种频率。
- 要做到 Politeness 要求还是需要 Single Host Queue 的。
- URL 就可以了。分配具体 crawl 机器可以由 Back Queue Selector 可以做分发。
- 可以的。Single Host Queue 的作用是保证 politeness 要求,不是处理 priority。
这里我也有同样的疑问,Crawl history里面记录有上次爬取的时间戳,那这个时间戳加上Domain policy里要求爬取频率,应该就可以满足politeness的要求了吧。这样的话感觉好像不需要使用single host queue,直接把prioritize queue里的URL根据这个条件分发给fetcher不行吗?
还有一个优先级的要求,其他情况一样的前提下,热门的URL先爬。
大概明白了,如果只有一组prioritize queue的话,selector没法跳过目前还不能爬的网址吧。比如虽然这个queue里有已经可以爬的了(frequency要求满足了),但是如果queue最前面的网址还不能爬,那就只能等着了。是不是有这个问题?
我觉得这里指的是对于同一个网站不要用太多的concurrent crawling
我说的不是你们讲的这个意思。Prioritized Queues 是为了在所有能爬的网站里找到优先级最高的先爬。
https://nlp.stanford.edu/IR-book/html/htmledition/the-url-frontier-1.html
Prioritized queue我明白的,我是想知道为什么还需要使用single host queue。不过后来我想明白了single host queue的好处是一个host下的URL不用和其它host互相等待,因为每个host有不同的policy,所以如果不把URL按照host分开放队列的话,有可能在队列头上的一直需要等到符合policy条件才能被爬,这样如果同一个queue里如果有别的host的话就被迫需要等待了
嗯嗯 是这个意思。