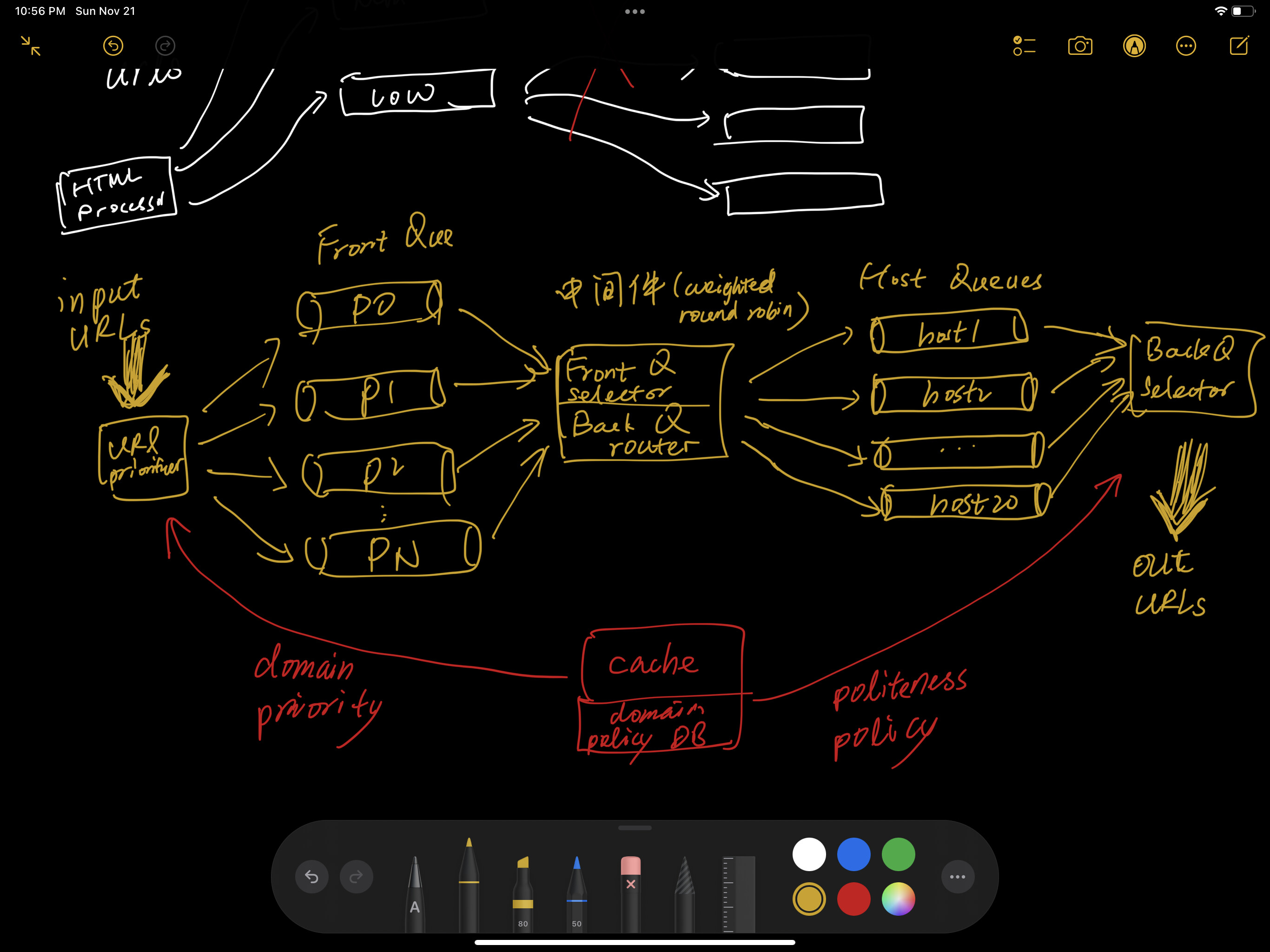
课程中说到 Front Queue 和 Back Queue之间有一个中间件。
- 请问中间件主动从Front Queue中poll结果吗并且按顺序 select from one of the front queue and route(inject into) back queue吗。
- 在真实场景中我们会选用什么软件来做这个中间见呢?
是RabbitMQ或者Kafka这样的软件吗?实际部署的时候会使用两个不同的MQ instances吗?
- 图中最左边的 URL prioritizer 和 最右边的 Back Queue Selector是单独的micro serivce吗?这些结构会出现 single point of failure 吗?