请教老师, 如何设计一个分布式的top K system 用来统计热门词汇, 类似于twitter的trending, 我想到的大致是类似auto complete system , 另外额外后台利用 map-reduce 来进行background job,老师是否有补充可否分享一些思路?
TopK 是有一节专题课的。这里提到的 MapReduce 可以用来实现一个允许较高延迟的 TopK System。在延迟敏感的情况下需要使用 Realtime streaming processing solution。这里又有两种可能:
- TopK over a Sliding Window
- TopK over entire history
可以使用不同的数据结构来实现。
假设 TopK over Sliding Window:
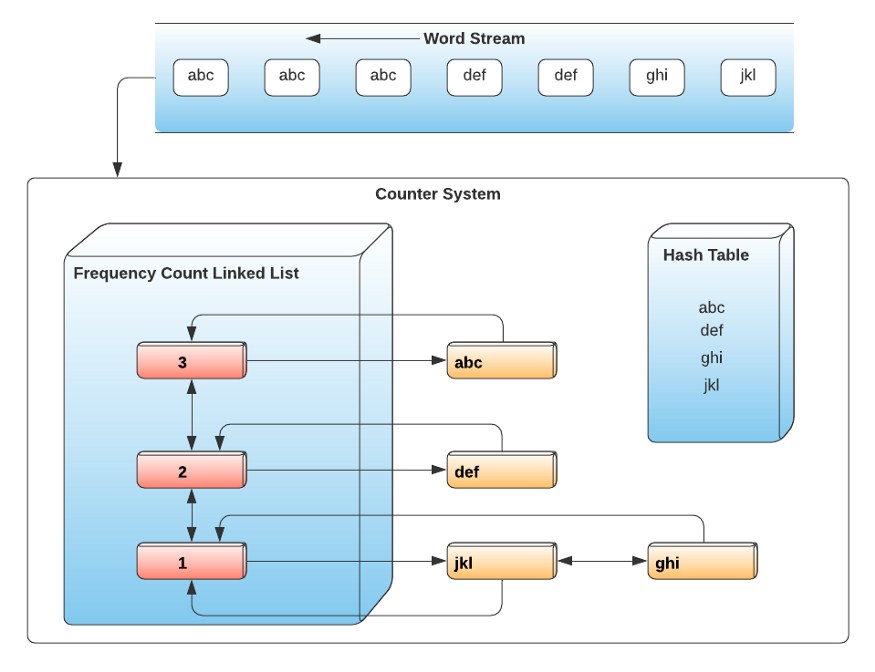
好的,谢谢老师的解答
老师这里的TopK over Sliding Window也是一台机器负责一部分的数据吗? 然后query的时候,有个aggregator负责向多台机器要数据然后汇总,最后返回top k?
是的,每台机器负责一个区间的数据,然后汇总。